Utilizing Cloud Native data formats with yt_xarray#
One of the benefits of linking yt to xarray dynamically is the access to the
well-developed methods within xarray to work with a range of file types, in particular
cloud-native formats like Zarr (CITATION). Additionally, because yt_xarray is careful
to delay data reads until required while maintaining links to the underlying xarray
dataset, the chunked reading possible with Zarr (or dask arrays).
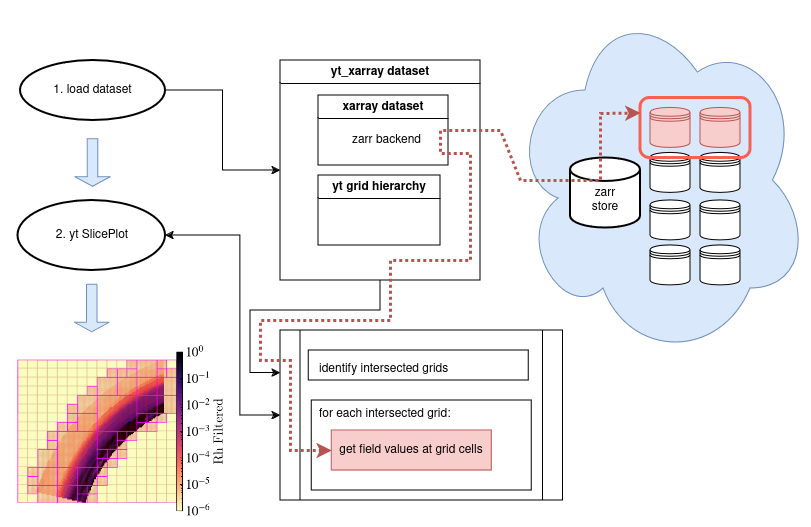
The flow chart above illustrates the steps and objects involved in the yt-xarray-Zarr
workflow. The steps visible to the user are at left: (1) load a dataset, (2) construct a slice plot
and then return an image. Behind the scenes, initially loading a yt_xarray dataset links the underlying xarray dataset within
a standard yt dataset and initializes the yt grid hierarchy. When a yt selection method
is applied, such as creating a slice plot (or extracting data from a geometric subselection), yt
first identifies grids within the hierarchy that intersect the selection object. For each grid
that is intersected (and only for those intersected), yt will fetch data at those grid cells.
At this point, yt will request data from the underlying xarray dataset.
At present, we are focusing on a number of complimentary avenues of development and research to improve analysis of cloud-native data with yt and yt_xarray. First, we are composite a set of tutorial notebooks demonstrating analysis workflows with yt_xarray that utilize subsets of cloud-hosted NASA Earth Observation Data in order to increase awareness and uptake of the current functionality. Additionally, we are investigating approaches to reading Zarr files from yt for both smoothed-particle hydrodynamics (SPH) simulation output and AMR grid structures.
yt can read and process output from a number of smoothed-particle hydrodynamics (SPH) simulations. These SPH simulations commonly store output in HDF files, and yt is enabled to read from and process particle data in chunks. While it may be possible to re-format many of these datasets in more cloud-ready formats like Zarr, it is also possible to obtain performant reads of existing cloud-hosted HDF files by using adding a simple fsspec metadata file that describes the HDF file and subseuqnetly loading a fsspec mapping object with Zarr (Signell, 2020). This approach should work well within yt’s SPH data readers and allow an immediate avenue to utilizing cloud-hosted data for yt operations that subselect data without needing to change existing output formats.
In addition to particle-base data yt can ingest multi-resolution gridded data stored in grid patches of variable refinement as well as octree structures and we are investigating ways of representing such AMR structures within the Zarr framework. The OME-Zarr format was designed to store multi-resolution pyramidal image data (Moore et all, 2023) and has overlap with the goals here and initial experiments embedding a gridded yt dataset within the napari experimental Generative Zarr reader showed signficant promise (Havlin, 2023). But pyramidal image structures differ from AMR structures in that AMR structures do not necessarily contain data for every level of refinement at every position and so representing the potential sparseness within Zarr requires additional considerations. We are currently exporing the use of both ragged array and awkward array structures to store AMR hierarchies, both of which have recent or in-progress Zarr representations.